Adding header size to width computation for srcline sort entry,
because it's possible to get empty data with ':0' which set width
of 2 which is lower than width needed to display column header.
Signed-off-by: Jiri Olsa <jolsa@kernel.org>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: David Ahern <dsahern@gmail.com>
Cc: Don Zickus <dzickus@redhat.com>
Cc: Joe Mario <jmario@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1474290610-23241-62-git-send-email-jolsa@kernel.org
[ Added declaration to sort.h ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Some macros required by tools/perf/trace/beauty/mmap.c is not support
for all architectures. For example, MAP_32BIT is defined on x86 only,
alpha doesn't define MADV_HWPOISON and MADV_SOFT_OFFLINE.
This patch regenerates mman.h for each arch, defines these missing
macros for perf. For missing MADV_*, fall back to asm-generic/mman-common
because they are in a 'case ...' statement. For flags, define it to 0.
Following is the script to generate this patch:
macros=`cat $0 | awk 'V==1 {print}; /^# start macro list/ {V=1}'`
rm `find ./tools/arch/ -name mman.h`
for arch in `ls tools/arch`
do
[ -d tools/arch/$arch/include/uapi/asm ] || mkdir -p tools/arch/$arch/include/uapi/asm
src=arch/$arch/include/uapi/asm/mman.h
target=tools/arch/$arch/include/uapi/asm/mman.h.tmp
real_target=tools/arch/$arch/include/uapi/asm/mman.h
guard="TOOLS_ARCH_"`echo $arch | awk '{print toupper($0)}'`_UAPI_ASM_MMAN_FIX_H
rm -f $target
[ -f $src ] &&
for m in $macros
do
if grep '#define[ \t]*'$m $src > /dev/null 2>&1
then
grep -h '#define[ \t]*'$m $src | sed 's/[ \t]*\/\*.*$//g' >> $target
fi
done
if [ -f $src ]
then
grep '#include <asm-generic' $src >> $target
else
echo "#include <asm-generic/mman.h>" >> $target
fi
touch $real_target
for m in $macros
do
if cat << EOF | gcc -Itools/arch/$arch/include -Itools/arch/$arch/include/uapi -Iinclude/ -Iinclude/uapi -E - | grep $m > /dev/null 2>&1
#include <uapi/asm/mman.h.tmp>
#include <uapi/linux/mman.h>
$m
EOF
then
echo "Fixing $m for $arch"
echo "/* $m is undefined on $arch, fix it for perf */" >> $target
if echo $m | grep '^MADV_' > /dev/null 2>&1
then
grep -h '#define[ \t]*'$m include/uapi/asm-generic/mman-common.h | sed 's/[ \t]*\/\*.*$//g' >> $target
else
echo "#define $m 0" >> $target
fi
fi
done
real_target=tools/arch/$arch/include/uapi/asm/mman.h
echo '#ifndef '$guard > $real_target
echo '#define '$guard >> $real_target
cat $target | sed 's|asm-generic|uapi/asm-generic|g' >> $real_target
echo '#endif' >> $real_target
rm $target
echo "$real_target"
done
exit 0
# Following macros are extracted from:
# tools/perf/trace/beauty/mmap.c
#
# start macro list
MADV_DODUMP
MADV_DOFORK
MADV_DONTDUMP
MADV_DONTFORK
MADV_DONTNEED
MADV_FREE
MADV_HUGEPAGE
MADV_HWPOISON
MADV_MERGEABLE
MADV_NOHUGEPAGE
MADV_NORMAL
MADV_RANDOM
MADV_REMOVE
MADV_SEQUENTIAL
MADV_SOFT_OFFLINE
MADV_UNMERGEABLE
MADV_WILLNEED
MAP_32BIT
MAP_ANONYMOUS
MAP_DENYWRITE
MAP_EXECUTABLE
MAP_FILE
MAP_FIXED
MAP_GROWSDOWN
MAP_HUGETLB
MAP_LOCKED
MAP_NONBLOCK
MAP_NORESERVE
MAP_POPULATE
MAP_PRIVATE
MAP_SHARED
MAP_STACK
MAP_UNINITIALIZED
MREMAP_FIXED
MREMAP_MAYMOVE
PROT_EXEC
PROT_GROWSDOWN
PROT_GROWSUP
PROT_NONE
PROT_READ
PROT_SEM
PROT_WRITE
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Tested-by: Kim Phillips <kim.phillips@arm.com>
Tested-by: Naveen N. Rao <naveen.n.rao@linux.vnet.ibm.com>
Cc: Ravi Bangoria <ravi.bangoria@linux.vnet.ibm.com>
Cc: Zefan Li <lizefan@huawei.com>
Cc: pi3orama@163.com
Fixes: 277cf08f3f ("perf trace beauty mmap: Fix defines for non !x86_64")
Link: http://lkml.kernel.org/r/1473850649-83389-3-git-send-email-wangnan0@huawei.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
This patch adds PMU driver specific configuration to the parser
infrastructure by preceding any term with the '@' letter. As such doing
something like:
perf record -e some_event/@cfg1,@cfg2=config/ ...
will see 'cfg1' and 'cfg2=config' being added to the list of evsel
config terms. Token 'cfg1' and 'cfg2=config' are not processed in user
space and are meant to be interpreted by the PMU driver.
First the lexer/parser are supplemented with the required definitions to
recognise the driver specific configuration. From there they are simply
added to the list of event terms. The bulk of the work is done in
function "parse_events_add_pmu()" where driver config event terms are
added to a new list of driver config terms, which in turn spliced with
the event's new driver configuration list.
Signed-off-by: Mathieu Poirier <mathieu.poirier@linaro.org>
Acked-by: Jiri Olsa <jolsa@kernel.org>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1473179837-3293-4-git-send-email-mathieu.poirier@linaro.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Now the hists__fprintf_hierarchy_headers() is a simple wrapper passing
field separator. Let's do it directly.
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/20160913074552.13284-6-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
When the --hierarchy option is used, each entry has its own hpp_list to
show the result. But it is not updating the width of each column for
perf-top. The perf-report command has no problem since it resets it
during header display.
$ sudo perf top --hierarchy --stdio
PerfTop: 160 irqs/sec kernel:38.8% exact: 100.0%
[4000Hz cycles:pp], (all, 12 CPUs)
----------------------------------------------------------------------
52.32% perf
24.74% [.] __symbols__insert
5.62% [.] rb_next
5.14% [.] dso__load_sym
Move the code into hists__fprintf() so that it can be called always.
Also it'd be better to put similar code together.
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Fixes: 1b2dbbf41a ("perf hists: Use own hpp_list for hierarchy mode")
Link: http://lkml.kernel.org/r/20160913074552.13284-5-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The hroot_in and hroot_out are roots of hierarchy trees of hist entries.
But when a hist entry is initialized by copying existing template entry,
it sometimes has non-empty tree and copies it incorrectly. This is a
problem especially when an event group is used since it creates dummy
entries from already-processed entries in other event members.
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/20160913074552.13284-4-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The hists__link_hierarchy() is to support hierarchy reports with an
event group. When it matches the leader event and the other members
(using hists__match_hierarchy()), it also needs to link unmatched member
entries with a dummy leader event so that it can show up in the output.
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/20160913074552.13284-3-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The hists__match_hierarchy() is to find matching hist entries in a
group. A matching entry has the same values for all sort keys given.
With an event group (e.g.: -e "{cycles,instructions}"), a leader event
should show other members in a group. So each entry in the leader
should be able to find its pair entries which have same values.
With hierarchy mode, it needs to search all matching children in a
hierarchy.
An example output looks like:
# Overhead Command / Shared Object / Symbol
# ...................... ..................................
#
25.74% 27.18% sh
19.96% 24.14% libc-2.24.so
9.55% 14.64% [.] __strcmp_sse2
1.54% 0.00% [.] __tfind
1.07% 1.13% [.] _int_malloc
...
In the above example, two overheads are shown - one for the leader and
another for the other group member. They were matched since their
command, dso and symbol have the same values.
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/20160913074552.13284-2-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
As with other cloned headers, compare the newly introduced mman related
headers against their source copy in kernel tree.
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Cc: Zefan Li <lizefan@huawei.com>
Cc: pi3orama@163.com
Link: http://lkml.kernel.org/r/1473684871-209320-4-git-send-email-wangnan0@huawei.com
[ Added -I to ignore the uapi/ difference ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The csets:
0ac3348e50 ("perf tools: Recognize hugetlb mapping as anon mapping")
d7e404af11 ("perf record: Mark MAP_HUGETLB when synthesizing mmap events")
Added code conditional on MAP_HUGETLB, to make it build in older systems
where that define wasn't available. Now that we grabbed copies of
uapi/linux/mmap.h to have all those definitions in tools/, use it so
that we can support building the tools for older systems (without the
MAP_HUGETLB define in its libc headers) using new kernels that support
such maps.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Cc: Zefan Li <lizefan@huawei.com>
Link: http://lkml.kernel.org/n/tip-wv6oqbfkpxbix4umj2kcfmaz@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Several defines have different values in different arches, so we can't
just define it to the x86_64 value, use uapi/linux/mmap.h that was
recently introduced to reliably find those, not using possibly outdated
libc headers.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Cc: Zefan Li <lizefan@huawei.com>
Link: http://lkml.kernel.org/n/tip-4eajp5yp8i2fuw44n7jmcg5t@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Some mmap related macros have different values for different
architectures. This patch introduces uapi mman.h for each
architectures.
Three headers are cloned from kernel include to tools/include:
tools/include/uapi/asm-generic/mman-common.h
tools/include/uapi/asm-generic/mman.h
tools/include/uapi/linux/mman.h
The main part of this patch is generated by following script:
macros=`cat $0 | awk 'V==1 {print}; /^# start macro list/ {V=1}'`
for arch in `ls tools/arch`
do
[ -d tools/arch/$arch/include/uapi/asm ] || mkdir -p tools/arch/$arch/include/uapi/asm
src=arch/$arch/include/uapi/asm/mman.h
target=tools/arch/$arch/include/uapi/asm/mman.h
guard="TOOLS_ARCH_"`echo $arch | awk '{print toupper($0)}'`_UAPI_ASM_MMAN_FIX_H
echo '#ifndef '$guard > $target
echo '#define '$guard >> $target
[ -f $src ] &&
for m in $macros
do
if grep '#define[ \t]*'$m $src > /dev/null 2>&1
then
grep -h '#define[ \t]*'$m $src | sed 's/[ \t]*\/\*.*$//g' >> $target
fi
done
if [ -f $src ]
then
grep '#include <asm-generic' $src >> $target
else
echo "#include <asm-generic/mman.h>" >> $target
fi
echo '#endif' >> $target
echo "$target"
done
exit 0
# Following macros are extracted from:
# tools/perf/trace/beauty/mmap.c
#
# start macro list
MADV_DODUMP
MADV_DOFORK
MADV_DONTDUMP
MADV_DONTFORK
MADV_DONTNEED
MADV_HUGEPAGE
MADV_HWPOISON
MADV_MERGEABLE
MADV_NOHUGEPAGE
MADV_NORMAL
MADV_RANDOM
MADV_REMOVE
MADV_SEQUENTIAL
MADV_SOFT_OFFLINE
MADV_UNMERGEABLE
MADV_WILLNEED
MAP_32BIT
MAP_ANONYMOUS
MAP_DENYWRITE
MAP_EXECUTABLE
MAP_FILE
MAP_FIXED
MAP_GROWSDOWN
MAP_HUGETLB
MAP_LOCKED
MAP_NONBLOCK
MAP_NORESERVE
MAP_POPULATE
MAP_PRIVATE
MAP_SHARED
MAP_STACK
MAP_UNINITIALIZED
MREMAP_FIXED
MREMAP_MAYMOVE
PROT_EXEC
PROT_GROWSDOWN
PROT_GROWSUP
PROT_NONE
PROT_READ
PROT_SEM
PROT_WRITE
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Cc: Zefan Li <lizefan@huawei.com>
Cc: pi3orama@163.com
Link: http://lkml.kernel.org/r/1473684871-209320-2-git-send-email-wangnan0@huawei.com
[ Added new files to tools/perf/MANIFEST to fix the detached tarball build, add mman.h for ARC ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Milian reported that the event group on TUI shows duplicated overhead.
This was due to a bug on calculating hpp->buf position. The
hpp_advance() was called from __hpp__slsmg_color_printf() on TUI but
it's already called from the hpp__call_print_fn macro in __hpp__fmt().
The end result is that the print function returns number of bytes it
printed but the buffer advanced twice of the length.
This is generally not a problem since it doesn't need to access the
buffer again. But with event group, overhead needs to be printed
multiple times and hist_entry__snprintf_alignment() tries to fill the
space with buffer after it printed. So it (brokenly) showed the last
overhead again.
The bug was there from the beginning, but I think it's only revealed
when the alignment function was added.
Reported-by: Milian Wolff <milian.wolff@kdab.com>
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Fixes: 89fee70943 ("perf hists: Do column alignment on the format iterator")
Link: http://lkml.kernel.org/r/20160912061958.16656-2-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
In 293d5b4394 ("perf probe: Support probing on offline cross-arch binary")
DWARF register tables were introduced for many architectures, with the one for
the "dx" register being broken for x86_64, which got noticed by the 'perf test
bpf' testcase, that has this difference from a successful run to one that
fails, with the aforementioned patch:
-Writing event: p:perf_bpf_probe/func _text+5197232 f_mode=+68(%di):x32 offset=%si:s64 orig=dx:s32
-Failed to write event: Invalid argument
-bpf_probe: failed to apply perf probe eventsFailed to add events selected by BPF
+Writing event: p:perf_bpf_probe/func _text+5197232 f_mode=+68(%di):x32 offset=%si:s64 orig=%dx:s32
Add the missing '%' to '%dx' to fix this.
Acked-by: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Fixes: 293d5b4394 ("perf probe: Support probing on offline cross-arch binary")
Link: https://lkml.kernel.org/r/20160909145955.GC32585@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
This patch implements the uncore monitoring driver for Skylake server.
The uncore subsystem in Skylake server is similar to previous
server. There are some differences in config register encoding and pci
device IDs. Besides, Skylake introduces many new boxes to reflect the
MESH architecture changes.
The control registers for IIO and UPI have been extended to 64 bit. This
patch also introduces event_mask_ext to handle the high 32 bit mask.
The CHA box number could vary for different machines. This patch gets
the CHA box number by counting the CHA register space during
initialization at runtime.
Signed-off-by: Kan Liang <kan.liang@intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vincent.weaver@maine.edu>
Link: http://lkml.kernel.org/r/1471378190-17276-3-git-send-email-kan.liang@intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
This patch enables RAPL counters (energy consumption counters)
support for Intel Apollo Lake (Goldmont) processors (Model 92):
RAPL of Goldmont, unlikes ESU increment of Silvermont/Airmont,
it likes the Haswell microarchitecture in 1/2^ESU joules and
supports power domains in PP0/PP1/PKG/RAM.
ESU and power domains refer to Intel Software Developers' Manual,
Vol. 3C, Order No. 325384, Table 35-12.
Usage example:
$ perf list
$ perf stat -a -e power/energy-cores/,power/energy-pkg/ sleep 10
Signed-off-by: Harry Pan <harry.pan@intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vincent.weaver@maine.edu>
Cc: bp@alien8.de
Cc: gs0622@gmail.com
Cc: hpa@zytor.com
Cc: srinivas.pandruvada@linux.intel.com
Link: http://lkml.kernel.org/r/1473325738-730-1-git-send-email-harry.pan@intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Alexander hit the WARN_ON_ONCE(!event) on his Skylake while running
the perf fuzzer.
This means the PEBSv3 record included a status bit for an inactive
event, something that _should_ not happen.
Move the code that filters the status bits against our known PEBS
events up a spot to guarantee we only deal with events we know about.
Further add "continue" statements to the WARN_ON_ONCE()s such that
we'll not die nor generate silly events in case we ever do hit them
again.
Reported-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Tested-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vince@deater.net>
Cc: stable@vger.kernel.org
Fixes: a3d86542de ("perf/x86/intel/pebs: Add PEBSv3 decoding")
Signed-off-by: Ingo Molnar <mingo@kernel.org>
At the moment, intel_bts will WARN() out if there is more than one
event writing to the same ring buffer, via SET_OUTPUT, and will only
send data from one event to a buffer.
There is no reason to have this warning in, so kill it.
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160906132353.19887-6-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Since BTS doesn't have a dedicated PMI status bit, the driver needs to
take extra care to check for the condition that triggers it to avoid
spurious NMI warnings.
Regardless of the local BTS context state, the only way of knowing that
the NMI is ours is to compare the write pointer against the interrupt
threshold.
Reported-by: Vince Weaver <vincent.weaver@maine.edu>
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160906132353.19887-5-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The intel_bts driver is using a CPU-local 'started' variable to order
callbacks and PMIs and make sure that AUX transactions don't get messed
up. However, the ordering rules in regard to this variable is a complete
mess, which recently resulted in perf_fuzzer-triggered warnings and
panics.
The general ordering rule that is patch is enforcing is that this
cpu-local variable be set only when the cpu-local AUX transaction is
active; consequently, this variable is to be checked before the AUX
related bits can be touched.
Reported-by: Vince Weaver <vincent.weaver@maine.edu>
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160906132353.19887-4-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The order of accesses to ring buffer's aux_mmap_count and aux_refcount
has to be preserved across the users, namely perf_mmap_close() and
perf_aux_output_begin(), otherwise the inversion can result in the latter
holding the last reference to the aux buffer and subsequently free'ing
it in atomic context, triggering a warning.
> ------------[ cut here ]------------
> WARNING: CPU: 0 PID: 257 at kernel/events/ring_buffer.c:541 __rb_free_aux+0x11a/0x130
> CPU: 0 PID: 257 Comm: stopbug Not tainted 4.8.0-rc1+ #2596
> Call Trace:
> [<ffffffff810f3e0b>] __warn+0xcb/0xf0
> [<ffffffff810f3f3d>] warn_slowpath_null+0x1d/0x20
> [<ffffffff8121182a>] __rb_free_aux+0x11a/0x130
> [<ffffffff812127a8>] rb_free_aux+0x18/0x20
> [<ffffffff81212913>] perf_aux_output_begin+0x163/0x1e0
> [<ffffffff8100c33a>] bts_event_start+0x3a/0xd0
> [<ffffffff8100c42d>] bts_event_add+0x5d/0x80
> [<ffffffff81203646>] event_sched_in.isra.104+0xf6/0x2f0
> [<ffffffff8120652e>] group_sched_in+0x6e/0x190
> [<ffffffff8120694e>] ctx_sched_in+0x2fe/0x5f0
> [<ffffffff81206ca0>] perf_event_sched_in+0x60/0x80
> [<ffffffff81206d1b>] ctx_resched+0x5b/0x90
> [<ffffffff81207281>] __perf_event_enable+0x1e1/0x240
> [<ffffffff81200639>] event_function+0xa9/0x180
> [<ffffffff81202000>] ? perf_cgroup_attach+0x70/0x70
> [<ffffffff8120203f>] remote_function+0x3f/0x50
> [<ffffffff811971f3>] flush_smp_call_function_queue+0x83/0x150
> [<ffffffff81197bd3>] generic_smp_call_function_single_interrupt+0x13/0x60
> [<ffffffff810a6477>] smp_call_function_single_interrupt+0x27/0x40
> [<ffffffff81a26ea9>] call_function_single_interrupt+0x89/0x90
> [<ffffffff81120056>] finish_task_switch+0xa6/0x210
> [<ffffffff81120017>] ? finish_task_switch+0x67/0x210
> [<ffffffff81a1e83d>] __schedule+0x3dd/0xb50
> [<ffffffff81a1efe5>] schedule+0x35/0x80
> [<ffffffff81128031>] sys_sched_yield+0x61/0x70
> [<ffffffff81a25be5>] entry_SYSCALL_64_fastpath+0x18/0xa8
> ---[ end trace 6235f556f5ea83a9 ]---
This patch puts the checks in perf_aux_output_begin() in the same order
as that of perf_mmap_close().
Reported-by: Vince Weaver <vincent.weaver@maine.edu>
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160906132353.19887-3-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
In the mmap_close() path we need to stop all the AUX events that are
writing data to the AUX area that we are unmapping, before we can
safely free the pages. To determine if an event needs to be stopped,
we're comparing its ->rb against the one that's getting unmapped.
However, a SET_OUTPUT ioctl may turn up inside an AUX transaction
and swizzle event::rb to some other ring buffer, but the transaction
will keep writing data to the old ring buffer until the event gets
scheduled out. At this point, mmap_close() will skip over such an
event and will proceed to free the AUX area, while it's still being
used by this event, which will set off a warning in the mmap_close()
path and cause a memory corruption.
To avoid this, always stop an AUX event before its ->rb is updated;
this will release the (potentially) last reference on the AUX area
of the buffer. If the event gets restarted, its new ring buffer will
be used. If another SET_OUTPUT comes and switches it back to the
old ring buffer that's getting unmapped, it's also fine: this
ring buffer's aux_mmap_count will be zero and AUX transactions won't
start any more.
Reported-by: Vince Weaver <vincent.weaver@maine.edu>
Signed-off-by: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@infradead.org>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: vince@deater.net
Link: http://lkml.kernel.org/r/20160906132353.19887-2-alexander.shishkin@linux.intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The resent conversion of the cpu hotplug support in the uncore driver
introduced a regression due to the way the callbacks are invoked at
initialization time.
The old code called the prepare/starting/online function on each online cpu
as a block. The new code registers the hotplug callbacks in the core for
each state. The core invokes the callbacks at each registration on all
online cpus.
The code implicitely relied on the prepare/starting/online callbacks being
called as combo on a particular cpu, which was not obvious and completely
undocumented.
The resulting subtle wreckage happens due to the way how the uncore code
manages shared data structures for cpus which share an uncore resource in
hardware. The sharing is determined in the cpu starting callback, but the
prepare callback allocates per cpu data for the upcoming cpu because
potential sharing is unknown at this point. If the starting callback finds
a online cpu which shares the hardware resource it takes a refcount on the
percpu data of that cpu and puts the own data structure into a
'free_at_online' pointer of that shared data structure. The online callback
frees that.
With the old model this worked because in a starting callback only one non
unused structure (the one of the starting cpu) was available. The new code
allocates the data structures for all cpus when the prepare callback is
registered.
Now the starting function iterates through all online cpus and looks for a
data structure (skipping its own) which has a matching hardware id. The id
member of the data structure is initialized to 0, but the hardware id can
be 0 as well. The resulting wreckage is:
CPU0 finds a matching id on CPU1, takes a refcount on CPU1 data and puts
its own data structure into CPU1s data structure to be freed.
CPU1 skips CPU0 because the data structure is its allegedly unsued own.
It finds a matching id on CPU2, takes a refcount on CPU1 data and puts
its own data structure into CPU2s data structure to be freed.
....
Now the online callbacks are invoked.
CPU0 has a pointer to CPU1s data and frees the original CPU0 data. So
far so good.
CPU1 has a pointer to CPU2s data and frees the original CPU1 data, which
is still referenced by CPU0 ---> Booom
So there are two issues to be solved here:
1) The id field must be initialized at allocation time to a value which
cannot be a valid hardware id, i.e. -1
This prevents the above scenario, but now CPU1 and CPU2 both stick their
own data structure into the free_at_online pointer of CPU0. So we leak
CPU1s data structure.
2) Fix the memory leak described in #1
Instead of having a single pointer, use a hlist to enqueue the
superflous data structures which are then freed by the first cpu
invoking the online callback.
Ideally we should know the sharing _before_ invoking the prepare callback,
but that's way beyond the scope of this bug fix.
[ tglx: Rewrote changelog ]
Fixes: 96b2bd3866 ("perf/x86/amd/uncore: Convert to hotplug state machine")
Reported-and-tested-by: Eric Sandeen <sandeen@sandeen.net>
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Borislav Petkov <bp@suse.de>
Link: http://lkml.kernel.org/r/20160909160822.lowgmkdwms2dheyv@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
User visible:
- Add branch stack / basic block info to 'perf annotate --stdio', where for
each branch, we add an asm comment after the instruction with information on
how often it was taken and predicted. See example with color output at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
(Peter Zijlstra)
- Only open an evsel in CPUs in its cpu map, fixing some use cases in
systems with multiple PMUs with different CPU maps (Mark Rutland)
- Fix handling of huge TLB maps, recognizing it as anonymous (Wang Nan)
Infrastructure:
- Remove the symbol filtering code, i.e. the callbacks passed to all functions
that could end up loading a DSO symtab, simplifying the code, eventually
allowing what we should have had since day one: removing the 'map' parameter
from dso__load() functions (Arnaldo Carvalho de Melo)
Arch specific build fixes:
- Fix detached tarball build on powerpc, where we were still accessing a
file outside tools/ (Ravi Bangoria)
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2
iQIcBAABCAAGBQJX0cvBAAoJENZQFvNTUqpApYEP/jrnFfmcz3KBMl2szCkKG8zF
Yl6kT31Og3BA595h4WlNpuKgFroPVj48H21ph/ZyxQWzQs9P9QrxcRKzERQKHOsl
NFtZi3Up7+/0Llfg5cTxNnIqsw2Zwud5shjnOGk6hMy1Q+Bt7JX9wYV17X+FJ1LT
YvDfIRo8wSJIGDJVnBAZrCFdQP3b2FztG9FQofwdO22FBBiEL6UYy+OemyXuN9XQ
fvaMgKE2Ib+DHBVjj6kTFCZOX67oHN8GcjFXCjAL+Nt1OL6/eUsJrdmKEpYPMzEU
HTov9AzqBoilF/9dd9on+73Yyyxo4QSMRkDW0b56kOFTP4JGdy0Fvvz9hFauGY+u
1vexWWI2pzIrY8+L2qNCtMV346zv74Pmp/YrgDtCjT8Vk4bmKbLv+TdmusEyfXPu
zouCqJnoAPxaTpwKV6QHjIZ9YV1nDhku5MAlJNKqQGPQvRFi2wChyyaHUjoXccK2
aSrWsEWw/yCnFe4Gelar5lQ5EoPBufV+d55MfCqufO8OoPurAjUiLcw2HO+h08Vo
4UdYph/RtmqlJJgSUBoLotyTkIf1YPWRpE+5E1NafgwmcqPLA0c+tlqctzg261KF
qg3nqmS/C1TwHhUMvBIL78GyWx7jIEJ6rdTnGAxArJjB3PLZ9PUoZ51NOlKp+NcU
dR5jWb8DBsmZRrjPxC9x
=LkPB
-----END PGP SIGNATURE-----
Merge tag 'perf-core-for-mingo-20160908' of git://git.kernel.org/pub/scm/linux/kernel/git/acme/linux into perf/core
Pull perf/core improvements and fixes from Arnaldo Carvalho de Melo:
User visible changes:
- Add branch stack / basic block info to 'perf annotate --stdio', where for
each branch, we add an asm comment after the instruction with information on
how often it was taken and predicted. See example with color output at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
(Peter Zijlstra)
- Only open an evsel in CPUs in its cpu map, fixing some use cases in
systems with multiple PMUs with different CPU maps (Mark Rutland)
- Fix handling of huge TLB maps, recognizing it as anonymous (Wang Nan)
Infrastructure changes:
- Remove the symbol filtering code, i.e. the callbacks passed to all functions
that could end up loading a DSO symtab, simplifying the code, eventually
allowing what we should have had since day one: removing the 'map' parameter
from dso__load() functions (Arnaldo Carvalho de Melo)
Arch specific build fixes:
- Fix detached tarball build on powerpc, where we were still accessing a
file outside tools/ (Ravi Bangoria)
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Signed-off-by: Ingo Molnar <mingo@kernel.org>
'make -C tools/perf build-test' is failing with below log for poewrpc.
In file included from /tmp/tmp.3eEwmGlYaF/perf-4.8.0-rc4/tools/perf/perf.h:15:0,
from util/cpumap.h:8,
from util/env.c:1:
/tmp/tmp.3eEwmGlYaF/perf-4.8.0-rc4/tools/perf/perf-sys.h:23:56:
fatal error: ../../arch/powerpc/include/uapi/asm/unistd.h: No such file or directory
compilation terminated.
I bisected it and found it's failing from commit ad430729ae ("Remove:
kernel unistd*h files from perf's MANIFEST, not used").
Header file '../../arch/powerpc/include/uapi/asm/unistd.h' is included
only for powerpc in tools/perf/perf-sys.h.
By looking closly at commit history, I found little weird thing:
Commit f2d9cae9ea ("perf powerpc: Use uapi/unistd.h to fix build
error") replaced 'asm/unistd.h' with 'uapi/asm/unistd.h'
Commit d2709c7ce4 ("perf: Make perf build for x86 with UAPI
disintegration applied") removes all arch specific 'uapi/asm/unistd.h'
for all archs and adds generic <asm/unistd.h>.
Commit f0b9abfb04 ("Merge branch 'linus' into perf/core") again
includes 'uapi/asm/unistd.h' for powerpc. Don't know how exactly this
happened as this change is not part of commit also.
Signed-off-by: Ravi Bangoria <ravi.bangoria@linux.vnet.ibm.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1472630591-5089-1-git-send-email-ravi.bangoria@linux.vnet.ibm.com
Fixes: ad430729ae ("Remove: kernel unistd*h files from perf's MANIFEST, not used")
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The perf tools can read a cpumask file for a PMU, describing a subset of
CPUs which that PMU covers. So far this has only been used to cater for
uncore PMUs, which in practice happen to only have a single CPU
described in the mask.
Until recently, the perf tools only correctly handled cpumask containing
a single CPU, and only when monitoring in system-wide mode. For example,
prior to commit 00e727bb38 ("perf stat: Balance opening and
reading events"), a mask with more than a single CPU could cause perf
stat to hang. When a CPU PMU covers a subset of CPUs, but lacks a
cpumask, perf record will fail to open events (on the cores the PMU does
not support), and gives up.
For systems with heterogeneous CPUs such as ARM big.LITTLE systems, this
presents a problem. We have a PMU for each microarchitecture (e.g. a big
PMU and a little PMU), and would like to expose a cpumask for each (so
as to allow perf record and other tools to do the right thing). However,
doing so kernel-side will cause old perf binaries to not function (e.g.
hitting the issue solved by 00e727bb38), and thus commits the
cardinal sin of breaking (existing) userspace.
To address this chicken-and-egg problem, this patch adds support got a
new file, cpus, which is largely identical to the existing cpumask file.
A kernel can expose this file, knowing that new perf binaries will
correctly support it, while old perf binaries will not look for it (and
thus will not be broken).
Signed-off-by: Mark Rutland <mark.rutland@arm.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Mark Rutland <mark.rutland@arm.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Will Deacon <will.deacon@arm.com>
Link: http://lkml.kernel.org/r/1473330112-28528-8-git-send-email-mark.rutland@arm.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
In systems with heterogeneous CPU PMUs, it's possible for each evsel to
cover a distinct set of CPUs, and hence the cpu_map associated with each
evsel may have a distinct idx<->id mapping. Any of these may be distinct
from the evlist's cpu map.
Events can be tied to the same fd so long as they use the same per-cpu
ringbuffer (i.e. so long as they are on the same CPU). To acquire the
correct FDs, we must compare the Linux logical IDs rather than the evsel
or evlist indices.
This path adds logic to perf_evlist__mmap_per_evsel to handle this,
translating IDs as required. As PMUs may cover a subset of CPUs from the
evlist, we skip the CPUs a PMU cannot handle.
Without this patch, perf record may try to mmap erroneous FDs on
heterogeneous systems, and will bail out early rather than running the
workload.
Signed-off-by: Mark Rutland <mark.rutland@arm.com>
Acked-by: Jiri Olsa <jolsa@kernel.org>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Mark Rutland <mark.rutland@arm.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Will Deacon <will.deacon@arm.com>
Link: http://lkml.kernel.org/r/1473330112-28528-7-git-send-email-mark.rutland@arm.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
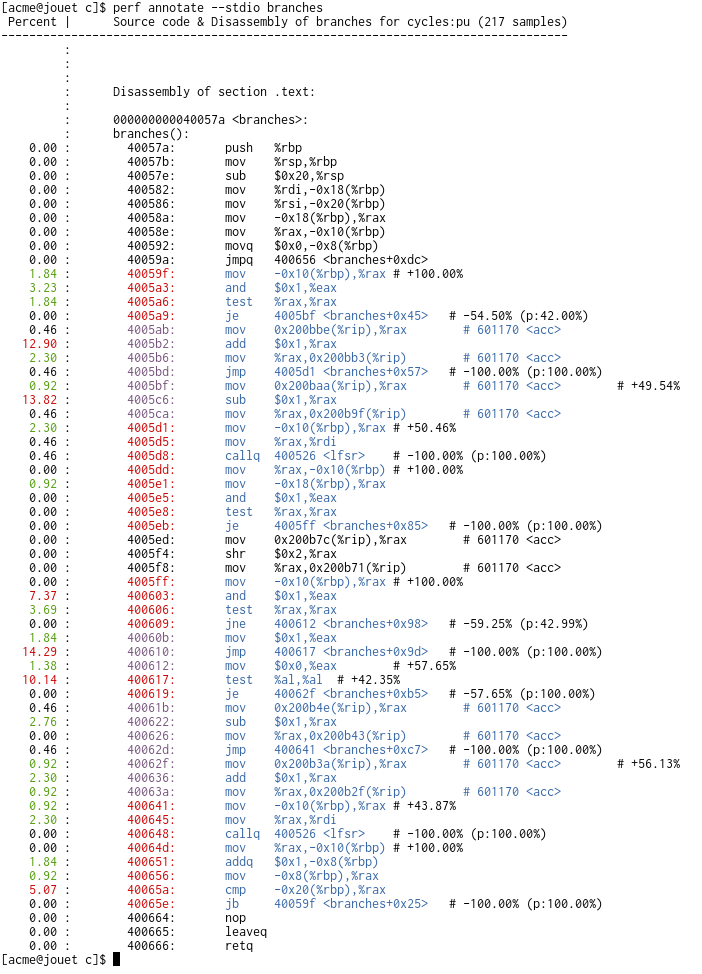
I wanted to know the hottest path through a function and figured the
branch-stack (LBR) information should be able to help out with that.
The below uses the branch-stack to create basic blocks and generate
statistics from them.
from to branch_i
* ----> *
|
| block
v
* ----> *
from to branch_i+1
The blocks are broken down into non-overlapping ranges, while tracking
if the start of each range is an entry point and/or the end of a range
is a branch.
Each block iterates all ranges it covers (while splitting where required
to exactly match the block) and increments the 'coverage' count.
For the range including the branch we increment the taken counter, as
well as the pred counter if flags.predicted.
Using these number we can find if an instruction:
- had coverage; given by:
br->coverage / br->sym->max_coverage
This metric ensures each symbol has a 100% spot, which reflects the
observation that each symbol must have a most covered/hottest
block.
- is a branch target: br->is_target && br->start == add
- for targets, how much of a branch's coverages comes from it:
target->entry / branch->coverage
- is a branch: br->is_branch && br->end == addr
- for branches, how often it was taken:
br->taken / br->coverage
after all, all execution that didn't take the branch would have
incremented the coverage and continued onward to a later branch.
- for branches, how often it was predicted:
br->pred / br->taken
The coverage percentage is used to color the address and asm sections;
for low (<1%) coverage we use NORMAL (uncolored), indicating that these
instructions are not 'important'. For high coverage (>75%) we color the
address RED.
For each branch, we add an asm comment after the instruction with
information on how often it was taken and predicted.
Output looks like (sans color, which does loose a lot of the
information :/)
$ perf record --branch-filter u,any -e cycles:p ./branches 27
$ perf annotate branches
Percent | Source code & Disassembly of branches for cycles:pu (217 samples)
---------------------------------------------------------------------------------
: branches():
0.00 : 40057a: push %rbp
0.00 : 40057b: mov %rsp,%rbp
0.00 : 40057e: sub $0x20,%rsp
0.00 : 400582: mov %rdi,-0x18(%rbp)
0.00 : 400586: mov %rsi,-0x20(%rbp)
0.00 : 40058a: mov -0x18(%rbp),%rax
0.00 : 40058e: mov %rax,-0x10(%rbp)
0.00 : 400592: movq $0x0,-0x8(%rbp)
0.00 : 40059a: jmpq 400656 <branches+0xdc>
1.84 : 40059f: mov -0x10(%rbp),%rax # +100.00%
3.23 : 4005a3: and $0x1,%eax
1.84 : 4005a6: test %rax,%rax
0.00 : 4005a9: je 4005bf <branches+0x45> # -54.50% (p:42.00%)
0.46 : 4005ab: mov 0x200bbe(%rip),%rax # 601170 <acc>
12.90 : 4005b2: add $0x1,%rax
2.30 : 4005b6: mov %rax,0x200bb3(%rip) # 601170 <acc>
0.46 : 4005bd: jmp 4005d1 <branches+0x57> # -100.00% (p:100.00%)
0.92 : 4005bf: mov 0x200baa(%rip),%rax # 601170 <acc> # +49.54%
13.82 : 4005c6: sub $0x1,%rax
0.46 : 4005ca: mov %rax,0x200b9f(%rip) # 601170 <acc>
2.30 : 4005d1: mov -0x10(%rbp),%rax # +50.46%
0.46 : 4005d5: mov %rax,%rdi
0.46 : 4005d8: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 4005dd: mov %rax,-0x10(%rbp) # +100.00%
0.92 : 4005e1: mov -0x18(%rbp),%rax
0.00 : 4005e5: and $0x1,%eax
0.00 : 4005e8: test %rax,%rax
0.00 : 4005eb: je 4005ff <branches+0x85> # -100.00% (p:100.00%)
0.00 : 4005ed: mov 0x200b7c(%rip),%rax # 601170 <acc>
0.00 : 4005f4: shr $0x2,%rax
0.00 : 4005f8: mov %rax,0x200b71(%rip) # 601170 <acc>
0.00 : 4005ff: mov -0x10(%rbp),%rax # +100.00%
7.37 : 400603: and $0x1,%eax
3.69 : 400606: test %rax,%rax
0.00 : 400609: jne 400612 <branches+0x98> # -59.25% (p:42.99%)
1.84 : 40060b: mov $0x1,%eax
14.29 : 400610: jmp 400617 <branches+0x9d> # -100.00% (p:100.00%)
1.38 : 400612: mov $0x0,%eax # +57.65%
10.14 : 400617: test %al,%al # +42.35%
0.00 : 400619: je 40062f <branches+0xb5> # -57.65% (p:100.00%)
0.46 : 40061b: mov 0x200b4e(%rip),%rax # 601170 <acc>
2.76 : 400622: sub $0x1,%rax
0.00 : 400626: mov %rax,0x200b43(%rip) # 601170 <acc>
0.46 : 40062d: jmp 400641 <branches+0xc7> # -100.00% (p:100.00%)
0.92 : 40062f: mov 0x200b3a(%rip),%rax # 601170 <acc> # +56.13%
2.30 : 400636: add $0x1,%rax
0.92 : 40063a: mov %rax,0x200b2f(%rip) # 601170 <acc>
0.92 : 400641: mov -0x10(%rbp),%rax # +43.87%
2.30 : 400645: mov %rax,%rdi
0.00 : 400648: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 40064d: mov %rax,-0x10(%rbp) # +100.00%
1.84 : 400651: addq $0x1,-0x8(%rbp)
0.92 : 400656: mov -0x8(%rbp),%rax
5.07 : 40065a: cmp -0x20(%rbp),%rax
0.00 : 40065e: jb 40059f <branches+0x25> # -100.00% (p:100.00%)
0.00 : 400664: nop
0.00 : 400665: leaveq
0.00 : 400666: retq
(Note: the --branch-filter u,any was used to avoid spurious target and
branch points due to interrupts/faults, they show up as very small -/+
annotations on 'weird' locations)
Committer note:
Please take a look at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
To see the colors.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Anshuman Khandual <khandual@linux.vnet.ibm.com>
Cc: David Carrillo-Cisneros <davidcc@google.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Stephane Eranian <eranian@google.com>
[ Moved sym->max_coverage to 'struct annotate', aka symbol__annotate(sym) ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
When synthesizing mmap events, add MAP_HUGETLB map flag if the source of
mapping is file in hugetlbfs.
After this patch, perf can identify hugetlb mapping even if perf is
started after the mapping of huge pages (like with 'perf top').
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Reviewed-by: Nilay Vaish <nilayvaish@gmail.com>
Cc: He Kuang <hekuang@huawei.com>
Cc: Hou Pengyang <houpengyang@huawei.com>
Cc: Zefan Li <lizefan@huawei.com>
Link: http://lkml.kernel.org/r/1473137909-142064-4-git-send-email-wangnan0@huawei.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Detect hugetlbfs. hugetlbfs__mountpoint() will be used during recording
to help identifying hugetlb mmaps: which should be recognized as anon
mapping.
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Reviewed-by: Nilay Vaish <nilayvaish@gmail.com>
Cc: He Kuang <hekuang@huawei.com>
Cc: Hou Pengyang <houpengyang@huawei.com>
Cc: Zefan Li <lizefan@huawei.com>
Link: http://lkml.kernel.org/r/1473137909-142064-3-git-send-email-wangnan0@huawei.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Hugetlbfs mapping should be recognized as anon mapping so user has a
chance to create /tmp/perf-<pid>.map file for symbol resolving. This
patch utilizes MAP_HUGETLB to identify hugetlb mapping.
After this patch, if perf is started before a program starts using huge
pages (so perf gets MMAP2 events from kernel), perf is able to recognize
hugetlb mapping as anon mapping.
Signed-off-by: Wang Nan <wangnan0@huawei.com>
Cc: He Kuang <hekuang@huawei.com>
Cc: Nilay Vaish <nilayvaish@gmail.com>
Cc: Zefan Li <lizefan@huawei.com>
Link: http://lkml.kernel.org/r/1473137909-142064-2-git-send-email-wangnan0@huawei.com
Signed-off-by: Hou Pengyang <houpengyang@huawei.com>
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Yanqiu Zhang reported kernel panic when using mbm event
on system where CQM is detected but without mbm event
support, like with perf:
# perf stat -e 'intel_cqm/event=3/' -a
BUG: unable to handle kernel NULL pointer dereference at 0000000000000020
IP: [<ffffffff8100d64c>] update_sample+0xbc/0xe0
...
<IRQ>
[<ffffffff8100d688>] __intel_mbm_event_init+0x18/0x20
[<ffffffff81113d6b>] flush_smp_call_function_queue+0x7b/0x160
[<ffffffff81114853>] generic_smp_call_function_single_interrupt+0x13/0x60
[<ffffffff81052017>] smp_call_function_interrupt+0x27/0x40
[<ffffffff816fb06c>] call_function_interrupt+0x8c/0xa0
...
The reason is that we currently allow to init mbm event
even if mbm support is not detected. Adding checks for
both cqm and mbm events and support into cqm's event_init.
Fixes: 33c3cc7acf ("perf/x86/mbm: Add Intel Memory B/W Monitoring enumeration and init")
Reported-by: Yanqiu Zhang <yanqzhan@redhat.com>
Signed-off-by: Jiri Olsa <jolsa@redhat.com>
Acked-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Vikas Shivappa <vikas.shivappa@linux.intel.com>
Cc: Tony Luck <tony.luck@intel.com>
Cc: stable@vger.kernel.org
Link: http://lkml.kernel.org/r/1473089407-21857-1-git-send-email-jolsa@kernel.org
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
We're not using it anymore, few users were, but we really could do
without it, simplify lots of functions by removing it.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-1zng8wdznn00iiz08bb7q3vn@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
We don't need to initialize that area as we're not using it afterwards,
leftover, ditch it.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-jb2un8buy4rqawz73mcdm1sn@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Including machines__set_symbol_filter(), not used anymore.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-7o1qgmrpvzuis4a9f0t8mnri@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Not needed, we already have code to prune aliases.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-1ysyce7qjgui93gi1efbjwhf@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
This was being done just in 'perf top', but grouping idle symbols should
be useful in other places as well, so remove one more symbol_filter_t
user by moving this to the symbol library.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-5r7xitjkzjr9jak1zy3d8u5l@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
User visible:
- Support generating cross arch probes, i.e. if you specify a vmlinux
file for different arch than the one in the host machine,
$ perf probe --definition function_name args
will generate the probe definition string needed to append to the
target machine /sys/kernel/debug/tracing/kprobes_events file, using
scripting (Masami Hiramatsu).
- Make 'perf probe' skip the function prologue in uprobes if program
compiled without optimization, using the same strategy as gdb and
systemtap uses, fixing a bug where:
$ perf probe -x ./test 'foo i'
When 'foo(42)' was used on the "./test" executable would produce i=0
instead of the expected i=42 (Ravi Bangoria)
- Demangle symbols for synthesized @plt entries too (Millian Wolff)
Documentation:
- Show default report configuration in 'perf config' example
and docs (Millian Wolff)
Infrastructure:
- Make 'perf test vmlinux' tolerate the symbol aliasing pruning done when
loading kallsyms and vmlinux (Arnaldo Carvalho de Melo)
- Improve output of 'perf test vmlinux' test, to help identify on the verbose
output which lines are warning and which are errors (Arnaldo Carvalho de Melo)
- Prep work to stop having to pass symbol_filter_t to lots of functions,
simplifying symtab loading routines (Arnaldo Carvalho de Melo)
- Honor symbol_conf.allow_aliases when loading kallsyms as well, it was using
it only when loading vmlinux files (Arnaldo Carvalho de Melo)
- Fixup symbol->end before doing alias pruning when loading symbol tables
(Arnaldo Carvalho de Melo)
- Fix error handling of lzma kernel module decompression (Shawn Lin)
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2
iQIcBAABCAAGBQJXyFXLAAoJENZQFvNTUqpAao8P/0eaVlqNAl0Ynz+HK6TGWj8+
z6lLMjgGhqQAssMJXOljhAcllOLlTgNN0qxd8DRCoNmOVOGuzJfKyEB1nI/1AZCr
IHhKRLpqFT+L/2Qkp/Qw5++a3PiR6BARL3oRS2mItv0FF4yCEJMTrIJAb7n16KWP
4txIchuCru1Du6ChpAunJYRgRaoHzI/ANuIuW6MhzhtNeyC0doR5LQfVoDNQy/Nc
thjSsNImjImqoCu8U9res7GzRRk6ugrF4dSgR2fXkL4vrcqoQ9y4TC8QU1+Ep/tj
Qc/GcBr3pB55OMHbCzAcI/B/rTfuD/qyQRwxCP+11AgBncgvhi7xnzYUyEPBCICp
VWDs0/dPvE/FuGcJFMgPNlaGSSdLDzeIFrnjnMK/Umk0fV6lkQ60J8kn/ywi/yGh
Zq8l1rUMM6gRf85/7kcAiili2GvpGAsv+R79QW7B1dTs+VfO0/CbhA98UTSQvWiH
3p0cFCAC4krnwMFbGpCZT2w4cPAmwozq29nHuzhKqF60v+rgVoaD80DxwORuDHBz
eZnqbm6gflzbF2SwxvBVYUaaMgAwOU+s/Fz2QDDHu+31B3AGCYEGJp88UjC4HBxf
WpvuNj5sL16ilWeTq1uQI7nhc7qu6UolysUahmRUz3pXoJe3n57ltj6mCZA+jPLj
Axv9VhRUBn2KQZaoDjPF
=zDiL
-----END PGP SIGNATURE-----
Merge tag 'perf-core-for-mingo-20160901' of git://git.kernel.org/pub/scm/linux/kernel/git/acme/linux into perf/core
Pull perf/core improvements and fixes from Arnaldo Carvalho de Melo:
User visible changes:
- Support generating cross arch probes, i.e. if you specify a vmlinux
file for different arch than the one in the host machine,
$ perf probe --definition function_name args
will generate the probe definition string needed to append to the
target machine /sys/kernel/debug/tracing/kprobes_events file, using
scripting (Masami Hiramatsu).
- Make 'perf probe' skip the function prologue in uprobes if program
compiled without optimization, using the same strategy as gdb and
systemtap uses, fixing a bug where:
$ perf probe -x ./test 'foo i'
When 'foo(42)' was used on the "./test" executable would produce i=0
instead of the expected i=42 (Ravi Bangoria)
- Demangle symbols for synthesized @plt entries too (Millian Wolff)
Documentation changes:
- Show default report configuration in 'perf config' example
and docs (Millian Wolff)
Infrastructure changes:
- Make 'perf test vmlinux' tolerate the symbol aliasing pruning done when
loading kallsyms and vmlinux (Arnaldo Carvalho de Melo)
- Improve output of 'perf test vmlinux' test, to help identify on the verbose
output which lines are warning and which are errors (Arnaldo Carvalho de Melo)
- Prep work to stop having to pass symbol_filter_t to lots of functions,
simplifying symtab loading routines (Arnaldo Carvalho de Melo)
- Honor symbol_conf.allow_aliases when loading kallsyms as well, it was using
it only when loading vmlinux files (Arnaldo Carvalho de Melo)
- Fixup symbol->end before doing alias pruning when loading symbol tables
(Arnaldo Carvalho de Melo)
- Fix error handling of lzma kernel module decompression (Shawn Lin)
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Signed-off-by: Ingo Molnar <mingo@kernel.org>
PERF_EF_START is a flag to indicate to the PMU ->add() callback that, as
well as claiming the PMU resources required by the event being added,
it should also start the PMU.
Passing this flag to the ->start() callback doesn't make sense, because
->start() always tries to start the PMU. Remove it.
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vincent.weaver@maine.edu>
Cc: mark.rutland@arm.com
Link: http://lkml.kernel.org/r/1471257765-29662-1-git-send-email-will.deacon@arm.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The offset of the counters for UPI and M2M boxes on Skylake server is
non-standard (8 bytes apart).
This patch introduces a custom flag UNCORE_BOX_FLAG_CTL_OFFS8 to
specially handle it.
Signed-off-by: Stephane Eranian <eranian@google.com>
Signed-off-by: Kan Liang <kan.liang@intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vincent.weaver@maine.edu>
Link: http://lkml.kernel.org/r/1471378190-17276-2-git-send-email-kan.liang@intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The method to build PCI bus to socket mapping is similar among
platforms. However, the PCI location which stores Node ID mapping could
vary between different platforms. For example, the Node ID mapping address
on Skylake server is different from the previous platform. Also, to
build the mapping for the PCI bus without UBOX, it has to start from
bus 0 on Skylake server.
This patch removes the current hardcoded implementation and adds
three parameters for snbep_pci2phy_map_init(). This way the Node ID mapping
address and bus searching direction can be configured according to
different platforms.
Signed-off-by: Kan Liang <kan.liang@intel.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Reviewed-by: Nilay Vaish <nilayvaish@gmail.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Stephane Eranian <eranian@google.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Vince Weaver <vincent.weaver@maine.edu>
Link: http://lkml.kernel.org/r/1471378190-17276-1-git-send-email-kan.liang@intel.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
This effectively reverts commit:
71e7bc2bab ("perf/core: Check return value of the perf_event_read() IPI")
... and puts in a comment explaining why we ignore the return value.
Reported-by: Vegard Nossum <vegard.nossum@gmail.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: David Carrillo-Cisneros <davidcc@google.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Fixes: 71e7bc2bab ("perf/core: Check return value of the perf_event_read() IPI")
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Pull x86 fix from Thomas Gleixner:
"A single fix for an AMD erratum so machines without a BIOS fix work"
* 'x86-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/AMD: Apply erratum 665 on machines without a BIOS fix
Pull timer fixes from Thomas Gleixner:
"Two fixlet from the timers departement:
- A fix for scheduler stalls in the tick idle code affecting
NOHZ_FULL kernels
- A trivial compile fix"
* 'timers-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
tick/nohz: Fix softlockup on scheduler stalls in kvm guest
clocksource/drivers/atmel-pit: Fix compilation error
generated by bcache)
- 2 other stable fixes for DM log-writes
- a stable fix for a DM crypt bug that could result in freeing pointers
from uninitialized memory in the tfm allocation error path
- a DM bufio cleanup to discontinue using create_singlethread_workqueue()
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJXybwpAAoJEMUj8QotnQNaVjIIALIS2erGyUquUcFALyGzK0So
f3GUA3+o/1ttkzkHvDwdgPO0CscVsAp71hMN+3+GrPtXJZRoqlE/w2QfGLYHvV++
xZR4+kBYuKrlo7+ldvjEi4KI2YtZ541QyaRez7Vy8XKDBo54cFe9oUnGznOYIC+2
+oH0d2w933rrFgsUa3RFa+8Qyv2ch6SAhDhn6oy0vk7HhH8MIGQKMDQEHVRbgfJ9
kG45wakb4rDDzmxqT+ZyA8rNk4sV+WanNVfj/7mww/NZe4HW+O7xMJTVgUqczADu
Sny4VhQOk6w4rpooDeJ2djWHUi8THtX1W616Owu701fmQ9ttALEw0xiZXEOYzBA=
=v6+u
-----END PGP SIGNATURE-----
Merge tag 'dm-4.8-fixes-4' of git://git.kernel.org/pub/scm/linux/kernel/git/device-mapper/linux-dm
Pull device mapper fixes from Mike Snitzer:
- a stable fix in both DM crypt and DM log-writes for too large bios
(as generated by bcache)
- two other stable fixes for DM log-writes
- a stable fix for a DM crypt bug that could result in freeing pointers
from uninitialized memory in the tfm allocation error path
- a DM bufio cleanup to discontinue using create_singlethread_workqueue()
* tag 'dm-4.8-fixes-4' of git://git.kernel.org/pub/scm/linux/kernel/git/device-mapper/linux-dm:
dm bufio: remove use of deprecated create_singlethread_workqueue()
dm crypt: fix free of bad values after tfm allocation failure
dm crypt: fix error with too large bios
dm log writes: fix check of kthread_run() return value
dm log writes: fix bug with too large bios
dm log writes: move IO accounting earlier to fix error path
{kind=link}